FAST UNIFORM VECTOR GRIDS WITH SCATTERED DATA INTERPOLATION IN C#
When tasked with showing continuous current flows based on scattered data, vector grids can come to the rescue. A regular two-dimensional grid with a vector in every cell helps you calculate the position and direction of a point as it moves through the grid. However, if you have scattered data to begin with, how can you generate a complete vector grid from it, and moreover, how can you it fast?
The problem
I was working on a project where a .NET application is given a set of water current vectors (taken by a boat moving across a body of water), and must generate a current flow animation out of it, on the fly. The application uses Google Maps to visualize this animation, making it necessary to generate animation parts tile-by-tile, for any zoom level. (Showing how to have Google Maps show animations rather than static bitmaps on its tiles is a story for another article).
The application has no advance knowledge of the data it will be given, so the animation generation code must run within a reasonable time (say up to 50ms per tile). A typical tile looks like below, where I’ve made a GIF file from the animation. In reality I use a PNG strip containing all the frames so that I can have alpha transparency, but I’ll stick with a GIF here for browser compatibility reasons:

This is a 256x256 tile, and there are 256 currents flowing through it (with their starting points in a 16x16 grid). These currents were calculated with the help of a vector grid, which looks like this:

The vector grid, in turn, was generated from the following input vectors, which were obtained from the source data:

That’s just four vectors to generate a smooth current flow animation. Actually, a few more are used, because I look at vectors in neighbouring tiles as well to make sure the tiles connect seamlessly, but it is still very sparse data. So how can you create a vector grid from this, fast?
A naive approach
Speed is key, so I set about putting together an algorithm to create a vector field from a set of source vectors, for a single map tile. I came up with this:
1) Create a field of 16x16 empty vectors (or whatever field grid resolution you need).
2) There may be very many source data vectors, but only some of them will be part of this vector field. Find the vectors that are within the field and place them in the corresponding cells, averaging the vectors if there is more than one to a cell.
3) Use a nearest-neighbour approach to fill any empty cells.
4) If there are no vectors at all, which will happen when no source data is within the vector field, find the nearest source data vector and copy it into all of the cells.
Source data size
In my case, there could be anywhere between 10,000 to 100,000 source vectors. That is not the kind of list you want your code to plow through many times. For this reason, it does so only once (in step 2), and matches vectors to cells in the vector grid.
Only if the entire grid remains empty, it will execute step 4 and go through the full list again to find the input vector that is closest to the vector field being generated.
Neighbouring fields
The flow visualization in one field must match the visualization in its neighbouring field. For this reason, I don’t just create a 16x16 vector grid, but actually 32x32, where I overlap the neighbouring vectors grids halfway. That way, I get reasonable matching, because any source vectors in that overlap are also taken into account.
Interpolation of missing cells
Step 3 is the naive step. For speed reasons, I decided that for fields with very sparse source data (like the example above), I would make each original data point radiate outwards, copying its vector to neighbouring fields until it met the data radiating from another point. When you have plenty of source data, that is, only a small percentage of the grid cells are empty, then this will work fine (and fast). However, when your data is very sparse, you’ll get this:

There is no smooth interpolation going on here, and you can clearly see where one area ends and another begins. Not good. This nearest-neighbour approach is fast however, and gives reasonable results under certain conditions. Its approach is simple:
while (there are empty cells left)
go through the grid and copy any existing cell
- to cell above (if empty)
- to cell below (if empty)
- to cell to the left (if empty)
- to cell to the right (if empty)
do not consider cells that were just filled this way
end This approach will go through the entire 32x32 grid at most 16 times or so, so it takes very little time.
Shepard’s Method
To get a smooth vector grid, even where source data is very sparse, a different approach is required. The Wikipedia page for Inverse Distance Weighting lists several approaches, where the simplest one is Shepard’s Method.
The pertinent definition from Wikipedia is:
A general form of finding an interpolated value u at a given point x based on samples ui(xi) for i = 1, 2, …, N using inverse distance weighting is an interpolating function:
where
is a simple inverse distance weighting function. x is a interpolated point, xi is a known point, d is a distance between x and xi and p is the power parameter.


Put another way, Shepard’s method helps find interpolated points in a regular grid from scattered data points by doing the following:
1) For each empty cell, calculate its distance to each cell with a known vector. Elevate that distance to a power p. Invert the distance. This is the weight of the known vector.
2) Multiply (scalar) known vectors by their weight, sum them up, then divide the resulting vector by the sum of all weights. This is the value for the new cell.
3) For cells with a known vector, do nothing.
A C# implementation would be something like this:
// We have a grid of vectors, which may be null
// for an empty cell:
Vector?[,] vectors;
// Shepard's method implementation. This takes
// a list of known points with vectors with a Point attribute
// (location) and Vector attribute:
private void Shepard(PointVector[] knownVectors)
{
// For each null-vector
for (int x = 0; x < GRID_SIZE; x++)
{
for (int y = 0; y < GRID_SIZE; y++)
{
if (vectors[x, y].HasValue) continue;
// Go through all known vectors and calculate each weight:
double totalWeight = 0;
double totalU = 0;
double totalV = 0;
foreach(PointVector v in knownVectors)
{
int dx = v.Point.X - x;
int dy = v.Point.Y - y;
double weight = Math.Sqrt(dx * dx + dy * dy);
weight = weight * weight * weight; // Power = 3
weight = 1 / weight;
totalU += weight * v.Vector.U;
totalV += weight * v.Vector.V;
totalWeight += weight;
}
vectors[x, y] = new Vector(totalU / totalWeight, totalV / totalWeight);
}
}
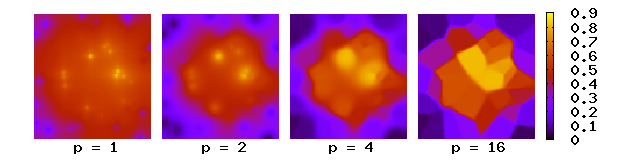
}Shepard’s method does not provide a unique solution to the scattered data problem. It has to be parameterized with a power, as each weight is elevated to a power p. The higher the power, the lesser the influence of far-away vectors on given point. In fact, high powers reduce the interpolation result to the naive implementation we had earlier, where there are clear boundaries between fields of influence, and it looks much like a Voronoi diagram. I’ve found that a power of 3 works well for a smooth interpolation.
Or, the way Wikipedia shows this:
Speeding things up
Now Shepard’s Method depends on calculating distances, which involves square roots, and these will take up a lot of CPU time. Also, raising weight to a power is requires several multiplications, which are costly, and there’s a division to calculate the inverse of the weight. In reality, it turns out that running the algorithm against a 32x32 grid is fairly fast (20 ms or so on average in my case, which I found not at all bad), but it can be seen that the time varies like this:
There are n empty cells and m known vectors, where n + m equals the total number of cells in the grid. The total number of calculations necessary to calculate the weight for every empty cell by calculating its distance to every known vector is n x m.
- For few empty cells and therefore many known vectors, the number of calculations is low.
- For many empty cells and therefore few known vectors, the number of calculations is low.
- For some empty cells and some known vectors, the number of calculations increases to a maximum where n = m, for a total of (n + m)2 calculations.
- The complexity is thus somewhere between O(n) (good) and O(n2) (not good).
Our grid, however, is a special case of Shepard’s Method. It’s not a continuous function, but rather a set of discrete values, and there aren’t very many values. For a grid of 32x32, there are only 1,024 cells. Not only is this not that many calculations (well, up to 262,144 in the worst case), but we can actually perform some precalculations that eliminate all the square roots, power elevations and divisions from the algorithm’s inner loop.
We’re always calculating the distance between some empty cell and a cell with a known vector. Since we’re working with a grid, there is always an X-distance and a Y-distance, and there are only so many combinations of these distances. For a 32x32 grid, there are in fact 32 X-distances (0, 1, 2, … 30, 31) and 32 Y-distances possible. That’s 32x32 = 1,024 combinations. Plus, we would only need to calculate results for just over half of these combinations, because a distance of (x=3, y=6) would have the same result as (x=6, y=3), so we could save some memory.
Without concerning ourselves with mirrored distances, however, we could simply do this:
double[,] weights = new double[GRID_SIZE, GRID_SIZE];
for(int x = 0; x < GRID_SIZE; x++) {
for(int y = 0; y < GRID_SIZE; y++) {
if(x == 0 && y == 0) continue; // Skip distance of zero
double weight = Math.Sqrt(x * x + y * y);
weight = weight * weight * weight; // Power = 3
weights[x,y] = 1 / weight;
}
}Now that we have an array of precalculated weights available, we can use it in Shepard’s Method:
private void Shepard(PointVector[] knownVectors)
{
// For each null-vector
for (int x = 0; x < GRID_SIZE; x++)
{
for (int y = 0; y < GRID_SIZE; y++)
{
if (vectors[x, y].HasValue) continue;
// Go through all known vectors and calculate each weight:
double totalWeight = 0;
double totalU = 0;
double totalV = 0;
foreach(PointVector v in knownVectors)
{
int dx = Math.Abs(v.Point.X - x);
int dy = Math.Abs(v.Point.Y - y);
double weight = weights[dx, dy];
totalU += weight * v.Vector.U;
totalV += weight * v.Vector.V;
totalWeight += weight;
}
vectors[x, y] = new Vector(totalU / totalWeight, totalV / totalWeight);
}
}
}This will reduce the number of calculations in the inner loop to just two multiplications, and a couple of divisions in the outer loop, making the whole algorithm take very little time to execute.